前言:
其实我一直想整理写出一篇这样的文章,将零散的体系稍微进行整合,用自己最通俗的语言解释数据库的索引。希望对看到且即将参加面试的人有所帮助。
首先,对于索引的基础知识方面你掌握了多少?
试着尝试来回答下面这几个问题吧
- 什么是二叉查找树?
- 什么是 B 树? 什么是 B+ 树?
- Mysql 索引为什么要使用 B+ 树?好处在哪儿?
- MyISAM 和 InnoDB 引擎是数据库级别还是数据表级别的?且文件存储上有什么区别?
- 什么是聚集索引、什么是非聚集索引,它们有着怎么样的数据结构?
- 如果数据表中没有主键,那么它存储的结构是什么形式的?
- 索引设计中,为什么我们更偏向于使用 B+ 树类型作为索引,而不是使用 Hash ?
- 你知道联合索引会在什么时候会失效吗?
- 为什么 MySQL 更推荐我们使用自增主键,而不去使用 UUID 作为主键?它的底层是怎么考虑的?
其实相信许多刚迈入IT行业的开发猿在找工作期间中多多少少遇到过这样的面试题,也许你是死记硬背过的,也许你只知其一不了解其二,因此请耐心的听我细细道来。
首先对于第一问什么是"二叉查找树" 有疑问的同学,我建议你可以先去补补基础的数据结构与算法概念,再来看看这篇文章也许收获更大。
一、什么是二叉查找树?
在引出二叉查找树前,我想先展示一个无序链表,如下图所示
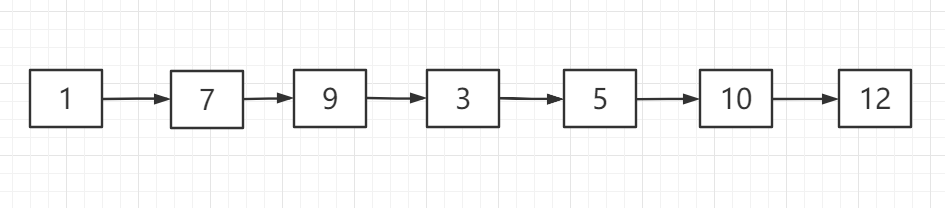
当计算机判断数值 12 是否存在于链表集合中时,最傻的方法是从左到右依次遍历出来每个值,查看它是否与 12 相等。凑巧 12 在链表的节点的最末端,因此它需要将整个链表遍历完才能得到结果。
因此我们将上面的链表进行变形,得到如下结构(二叉查找树):
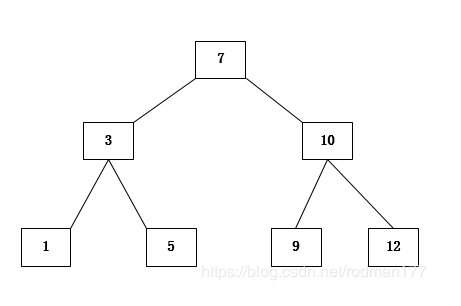
让我们看看它的定义:
根节点的值大于其左子树中任意一个节点的值,小于其右节点中任意一节点的值,这一规则适用于二叉查找树中的每一个节点。
很明显,我们能发现,位于根节点的值永远大于它左边的左子树,小于右边的右子树。同理我让计算机判定数值 12 是否存在这个结构中,只需要进行三次查找即可。
7 -> 10 ->12
但是,二叉搜索树真有这么快且不存在极端情况吗?
我们再根据它的定义,细细品品这句话,"根节点的值小于其右节点中任意一节点",来看看它的极端情况。
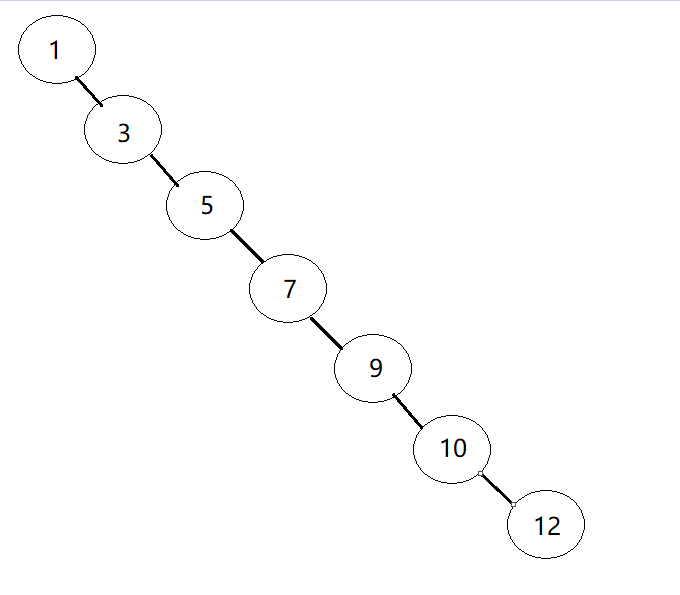
很明显根据定义,这是颗只有右子树的二叉查找树,并且他和上图每个节点的值都一样,我们可以拿高中化学中所学的同分异构体来看待。
目前已经退化成链表的形式。当我们要查找数值 12 是否存在还是需要将整颗树完完整整的遍历一遍。(有同学可能会说,用二分法呀,不用全部遍历.....请注意这里是树结构,不是数组)
由上面可以得知,二叉搜索树的退化会造成树的高度急剧升高,进而转换成链表,在数据库索引中,每从根节点往子节点跳一层,都会进行一次磁盘IO操作。如果把它当做数据库索引,他要经过7次磁盘IO才能找到这个数值 12 。
二、什么是 B 树、B+树?
(一) B树 = 多叉平衡查找树
由上文我们可以得知,索引使用二叉查找树时,有可能会退化转换成链表,从而加大IO次数。那么有什么方法可以解决呢?
答案很明显,我们可以减少树的层级,也就是在同一层中容纳更多的节点。此时它不再是二叉查找树,而变成了一棵多叉平衡查找树。如下图所示
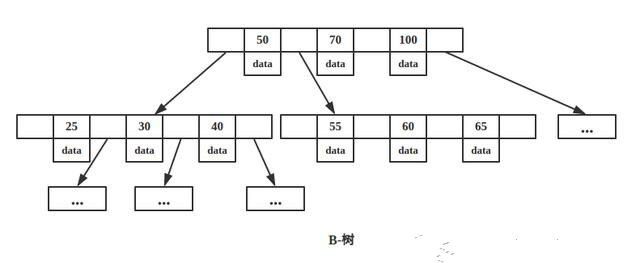
减少了树的高度就等于减少IO次数,每读取一层就是一次IO操作,并且它不存在退化为链表的情况,因为它是平衡树。
B树的每一个节点还会存储一个data域,data域里存储的是所对应记录的磁盘地址。
因此,当你查找到该索引时,通过 data 域存储的磁盘地址,你就能将一条完整的数据表记录取出。
然而这样真的就完美了吗?其实MySQL中使用的 B+树 而不是 B 树。
上一章节我提过,对树的每一层读取都是一次IO行为。比如我要读取 25 所对应的这条完整记录,因此肯定会加载树的第一层,但是很明显,我只需要加载第一层的 50、70、100三个值与25比对大小即可,完全没必要读取data域。
然而事实它会将三个值以及各自的 data 域都读取到内存中,这完全就造成了浪费,反而增大了 IO 行为。
此外,树的每一节点我们称之为一个索引页,MySQL 规定一个页的大小只有16KB,因此如果有 data 域的存在,必定占用了这一层的空间。
那么何时再读取 data 域最为合适呢?很明显,当我真正找到 25 这个记录时,再读取 data 域即可。
(二) B+树
因此真正MySQL数据存储的索引如下图所示 (B+树)
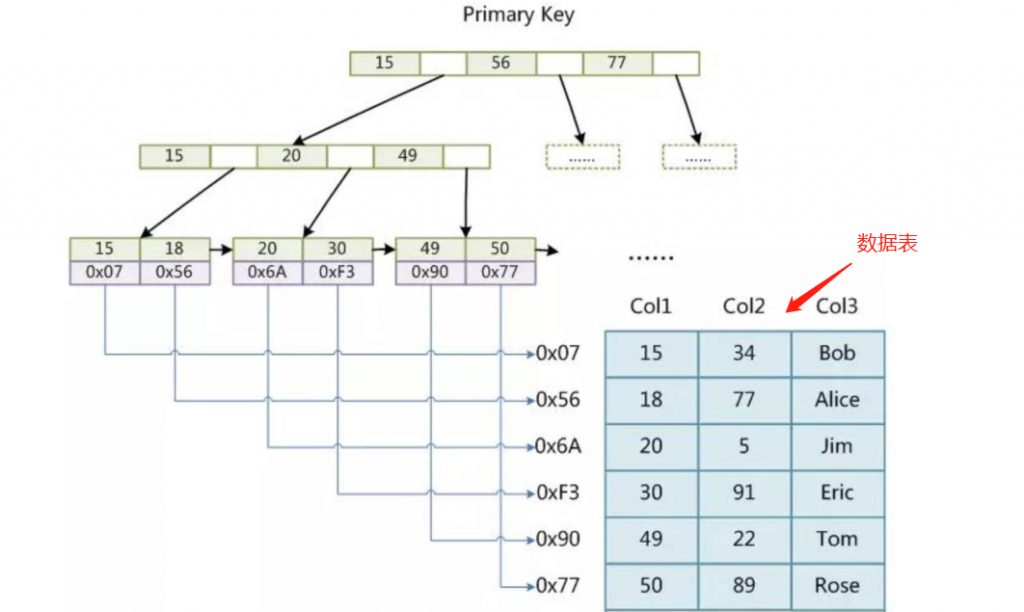
很明显能看到,只有叶子节点存储记录地址。非叶子节点层级少了 data 域后节省了空间,可以存储更多的索引,优势自然而然的就体现出来了。
即:B+树在同一层级的存储的索引个数比B树更多,并大大减少了 IO。
并且他还有个更加关键的特性,叶子结点是一个排好序的链表结构,每一个节点指向它下一个节点的地址,在下文我会解释这样做的好处。(PS:其实是双向链表,图中的单向是错误的)
三、 MyISAM 与 InnoDB
有同学只听过数据库引擎分为 MyISAM 与 InnoDB 就理所当然的以为是数据库引擎属于数据库级别,其实这是一个基础知识,它属于表级别。
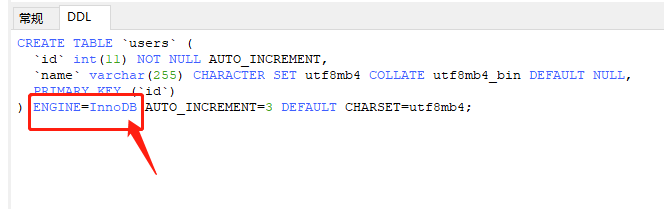
上图是一条建表语句,一个库中的表可以是 InnoDB 也可以是 MyISAM ,甚至也可以二者都存在,但他们的存储形式是怎么样的呢?
我们可以看到, 上图建表语句中的 users 表是 InnoDB引擎 ,它所对应的实际存储文件只有两个,如下所示:
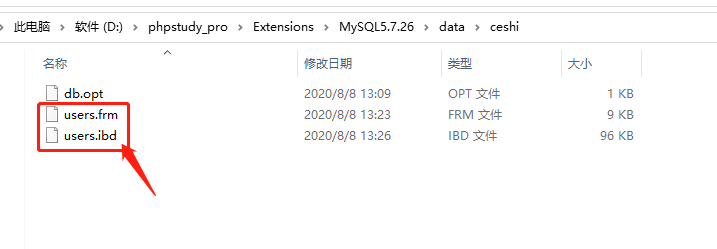
后缀为.frm 是users 表的表结构,而后缀为.ibd的文件是存储记录与索引的文件。
让我们再来看看 MyISAM 存储文件的形式:
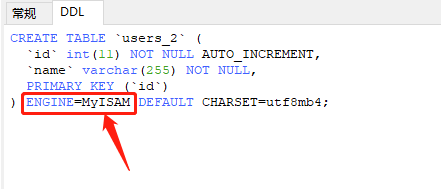
我创建 users_2 表,引擎设置为 MyISAM,它的文件存储结构如下:

先前提过.frm后缀是描述表结构文件, 而后缀.MYD是users_2表的数据存储文件,后缀.MYI是数据表的索引文件。
因此我们很明显的就能看出,InnoDB存储的引擎,将数据和索引存储在了一个存储文件中,然而 MyISAM 是将数据和索引分开来存储。这就体现了MyISAM的另一个特性,非聚集。
四、聚集索引和非聚集索引
MyISAM 引擎存储的索引类型就是非聚集索引
我们复用下面这张图,
如上图所示,当它寻找到叶子节点所在索引的 data域,然后他还需要根据 data 域中的地址去寻找完整的数据记录。因此索引不存储具体的记录,只存储记录的地址称之为非聚集索引。我们从 MyISAM 的文件中就可以看出这一特性,数据文件没有和索引存储在一块,自然而然的就能理解其中的缘由了。
相反 InnoDB 的聚集索引如下图所示:
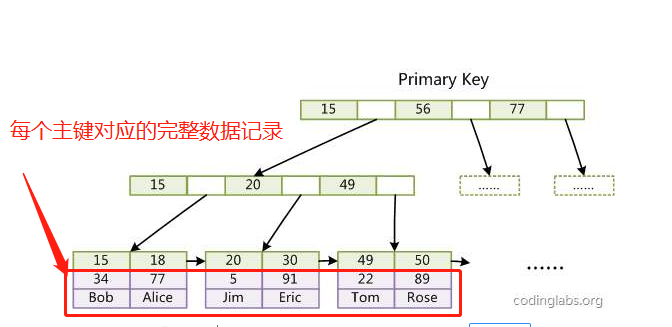
叶子结点的 data域 存储着主键与完整的记录,因此 InnoDB的 主键一般都是聚集索引,并且一张数据表只有一个主键,你通过主键作为查询条件,就能最快的访问到完整的记录。
在此来一个小的总结: InnoDB 主键存储的结构是聚集索引,他的 data 域存储的不是地址,而是一条完整的记录。而 MyISAM 的主键存储的是非聚集索引,他们的 data 域存储的是记录所在的磁盘地址。
然而对非主键字段设置的索引其实也是非聚集索引,他们的 data 域实际上存储的是对应主键的值,当使用非主键字段作为条件查询时,它会读取到它们各自所在的 data 域(即:主键的值),然后再通过查询主键所在位置获取到完整的记录。
五、没有主键的表结构是怎么样的
MySQL建议我们每一张表至少都要有一个主键,如果我们再一张表中不主动设计主键,当建表时它将会生成隐藏列作为主键,并且还是以 B+ 树形式构建。
六、索引设计中,为什么我们更偏向于使用 B+ 树类型作为索引,而不是使用 Hash
有的人可能会有所疑问,为什么大多数索引不能使用 Hash? Hash的散列查找能够更快直击目标,
这里我举示例:
当一条sql语句是这样的:
|
1 |
select * from users where age= 20; |
如果我们将 age 字段所在列使用 hash 索引的方法确实能够精准又快速的将结果搜索出。
但是如果sql语句是这样的呢?
|
1 |
select * from users where age > 20; |
此时 hash 索引的作用则会失效。
但是B+树则不会,因为它的叶子节点是个排好序的链表结构,我们可以瞬间引用右侧所有的节点,即 age>20 如下图所示:
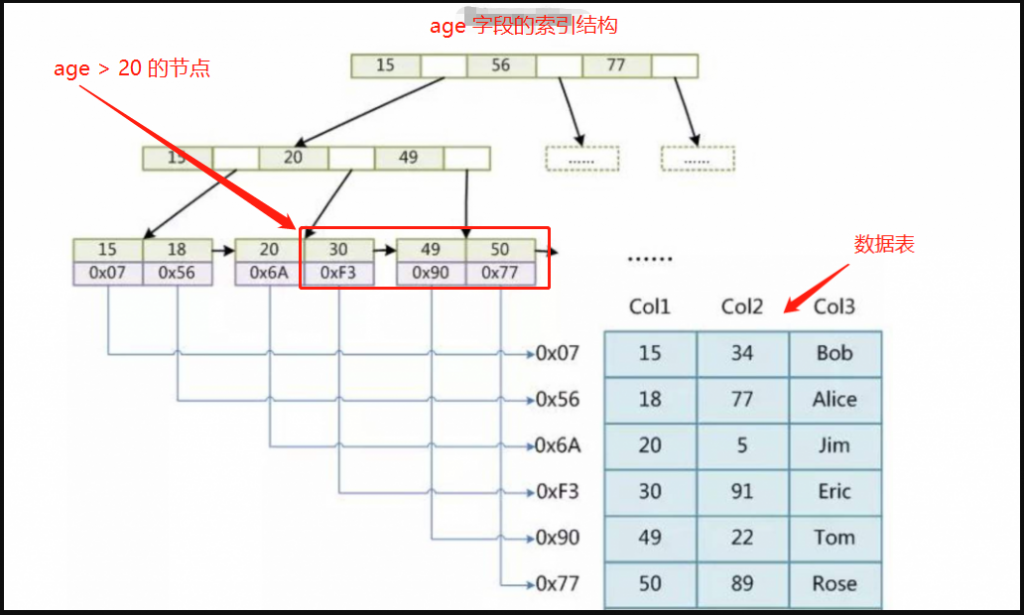
七、你知道联合索引会在什么时候会失效吗?
假设我有一张职工信息表,并且里面共有四个字段,分别是name、age、position、date(即:姓名、年龄、职位、入职日期)
并且我将 name、age、postion作为联合索引,他则是这个形式
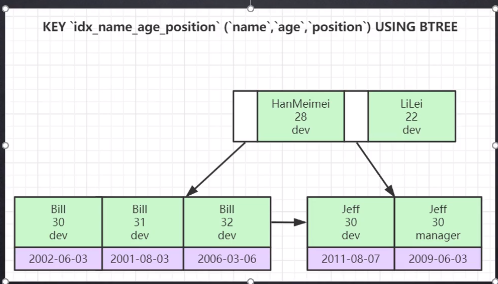
它依然遵循查找树的排序规则,只不过联合索引是根据字段的先后顺序进行排序,由于姓名为第一个字段,因此HanMeimei的节点第一个字符是以H开头,自然小于L字符开头的LiLei。因此排在左侧。此外我们看第二层,当姓名都为 Bill 的节点无法比较大小时才会选取第二个字段年龄进行比较。依次类推,当年龄无法比较大小时会选取职位进行排序比较。
此时根据上面的结构且我拥有三条 sql 语句,那么哪条 sql 会索引失效呢?
|
1 2 3 |
select * from employee where name = 'Bill' and age =31; # 第一条 select * from employee where age= 30 and position ='dev'; # 第二条 select * from employee where position ='manager';# 第三条 |
答案是:二、三两条都会失效,这是因为执行第一条时,我们先使用条件 name= Bill,则第一步会使用 Bill 和 HanMeimei 比较大小,很明显H>B,所以B在左子树(使得索引生效),但后两条由于没有比较 name 字段,使得整个联合索引都将失效。
这称之为:索引的最左前缀原则(由于 name 是第一个字段,因此它是最左前缀)
八、为什么MySQL推崇自增主键,而不是UUID
我看过部分文章,有些文章表示,使用UUID作为业务主键更为合适,他们的想法是,假设一张订单表使用自增主键,当我们查询订单时的url肯定将是 xxx/order/20的形式,这样我大早上购物和晚上购物通过url后缀的差值就能计算出一天的订单量,这显然暴露了公司机密。主键应该是无业务意义的。并且由于自增主键的影响下不好进行分库分表操作。
但是在查询方面,UUID是字符串类型,所占字节较大,相比自增主键,在树的同一层级存储的索引个数将会大大减少(注:前面提到过,一层最多16KB),此时必然会增加树的高度,并且建立查找树时,需要对每一个字符串进行字符比对,假设两个 uuid 分别为:aaaaabc 与 aaaaabd,此时需要将字符比对到最后一位才能比对出结果,大大降低了查找速度,并且当它写入数据来调整整颗平衡树时所需的开销也会巨大无比。
这篇文章将近写了5个小时,才疏学浅还需指正。
兰陵美酒郁金香
大道至简 Simplicity is the ultimate form of sophistication.
文章评论(0)