一、前言
在公司我们应当需要一套监控系统来保障我们的业务。任何人都无法保证自己写的项目毫无bug或者不会出现OOM的情况。
不巧,前段时间我刚开发的业务上线后不久就出现了 goroutine 泄露的事故。由于 goroutine 占用内存的大小很小,因此服务没有报警。
那么我们是如何观测到 goroutine 泄露的呢?还是监控系统帮了大忙。
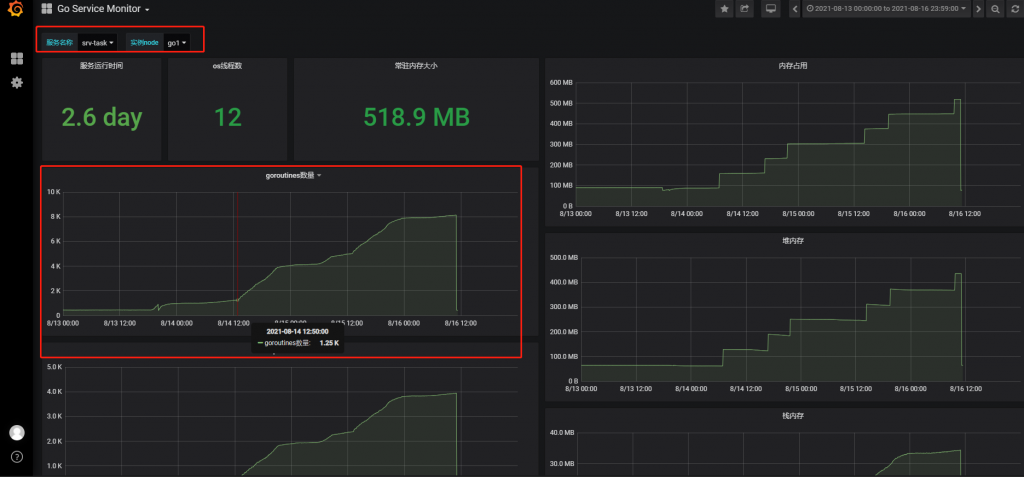
我们不仅要监控宿主机,同时也要兼顾到每一个服务的的 CPU 、内存、IO资源。做到最粒度化的监控。
比如说,原本一个后端服务的CPU占用只有 30%,但是突然有一天飙升到 60 %,那么你势必就要留心了。如果你是 Golang 开发人员,这势必需要你通过使用 pprof+trace 去排查。
但以上都是后话了,前提是你能发现你的服务异常。因此一套监控系统就无比重要。
二、基本介绍
关于 Prometheus 、Grafana 的介绍网上多的是,我这里就不进行复制黏贴了。简单的来说 Prometheus 是用来收集监控数据的,启动它时他会监听在 9090 端口。并且他会收集各服务的数据。而 Grafana 是一个可视化工具,它可以通过图表等形式将大量数据以更直观的形式展示在开发人员面前。
三、安装
1.Prometheus的安装
下载地址:https://prometheus.io/download/
根据你的操作系统自行进行安装,作者这里使用的是 linux-amd
下载后解压后如下图所示
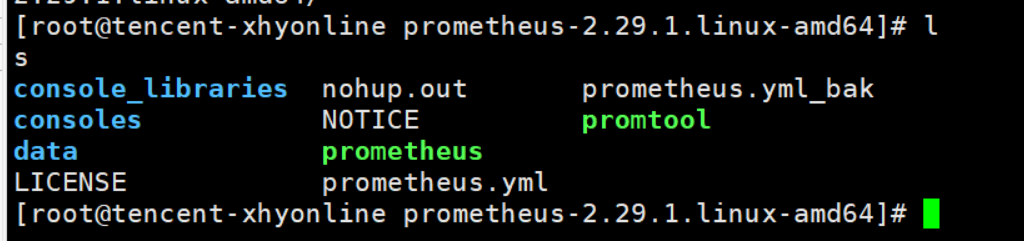
暂时将目光放在三个文件上,分别是两个可执行文件prometheus、 promtool,以及一个配置文件 prometheus.yml
文件介绍如下
promtool是一个工具,你可以用它来检测配置文件是否配置正确,例如你使用下面的命令./promtool check config ./prometheus.ymlpromethus就是启动程序prometheus.yml配置文件
启动命令:./prometheus --config.file=prometheus.yml
2. Grafana 安装
下载地址:https://grafana.com/grafana/download?pg=get&plcmt=selfmanaged-box1-cta1
请根据你自己的操作系统进行下载
作者这里直接下载二进制程序,请上传到服务器后自行进行解压
解压后请进入bin 目录

cd bin进入目录后你就能看到以下文件

启动命令也无比简单,他默认会启动在 3000 端口
./grafana-server三、上手实操
1.准备
- 准备两台虚拟机,或者云服务器 (PS:这里主要是实操多机器监控)
- 准备两个 Go 程序,部署在机器1上与机器2上。(PS:作者这里在1号服务器上部署了两个go程序,下面就叫这两个程序为server1和server2吧。但是在2号服务器上只部署了server1)
2.编写代码与配置文件
2.1 编写 Golang 程序
server1 的代码如下:(模拟CPU+Goroutine涨幅)
package main
import (
"github.com/xhyonline/xutil/helper"
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
// 用来模拟 CPU 涨幅
var count = 0
go func() {
for {
count += helper.GetRandom(10)
count -= helper.GetRandom(10)
// 随机睡眠时间
time.Sleep(time.Nanosecond * time.Duration(helper.GetRandom(1000)))
}
}()
// 模拟 goroutine 涨幅与下降代码
go func() {
for {
go func() {
time.Sleep(time.Second * time.Duration(helper.GetRandom(5)))
}()
time.Sleep(time.Second * time.Duration(helper.GetRandom(5)))
}
}()
// 注册 prometheus 监控指标
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe("0.0.0.0:2112", nil)
}
server2代码如下:(只模拟 goroutine涨幅 )
package main
import (
"github.com/xhyonline/xutil/helper"
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
go func() {
for {
go func() {
time.Sleep(time.Second * time.Duration(helper.GetRandom(10)))
}()
time.Sleep(time.Second * time.Duration( helper.GetRandom(10)))
}
}()
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe("0.0.0.0:2113", nil)
}
也许你已经注意到了代码中有一个方法,如下所示
http.Handle("/metrics", promhttp.Handler())你可以运行server程序,然后通过/metrics的形式访问到这些监控数据。而promethus 会定时去 /metrics 下采集监控数据,然后通过 Grafana 展示。如下图所示

最后就是将这两个服务部署在两台机器上(1号服务器不是server1、server2,然后2号服务器只部署server1)
2.2 修改 promethues.yml 文件
我们仅需修改 scrape_configs 下的内容成如下
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "go1" # 服务器1号,我们暂时就将它命名为 go1 吧,他下面有两个服务
static_configs:
- targets: ["ip:2112"] # Prometheus 会定时去 ip:2112/metrics 下抓取数据,请自行把 ip 改成你服务地址
labels:
server_name: server1 # 第一个服务,也就是上面这个 ip:2112
- targets: ["ip:2113"] # Prometheus 会定时去 ip:2113/metrics 下抓取数据,请自行把 ip 改成你服务地址
labels:
server_name: server2 # 第二个服务,也就是上面这个 ip:2113
- job_name: "go2" # 服务器2号,它下面只有一个服务,也就是 server1 的副本
static_configs:
- targets: ["ip:2112"]
labels:
server_name: server1启动 promethues
./prometheus --config.file=prometheus.yml2.3 启动Grafana
./grafana-server2.3 进入 grafana
如下所示:
默认账号密码都是 admin
首次登录会让你重置密码
2.3.1 设置数据源
Grafana 需要从 Prometheus 里获取数据,因此你需要将这两个程序关联,因此第一步就是设置数据源。
如下图所示:
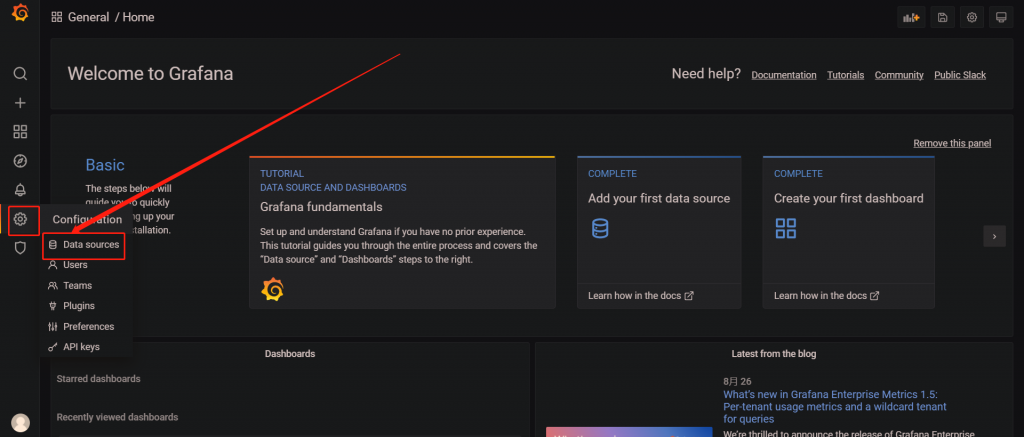
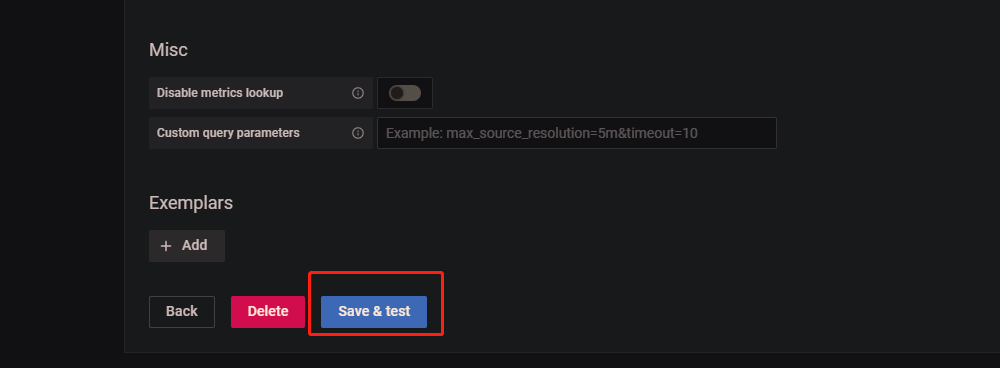
点击 Add data source 后就可以设置数据源了
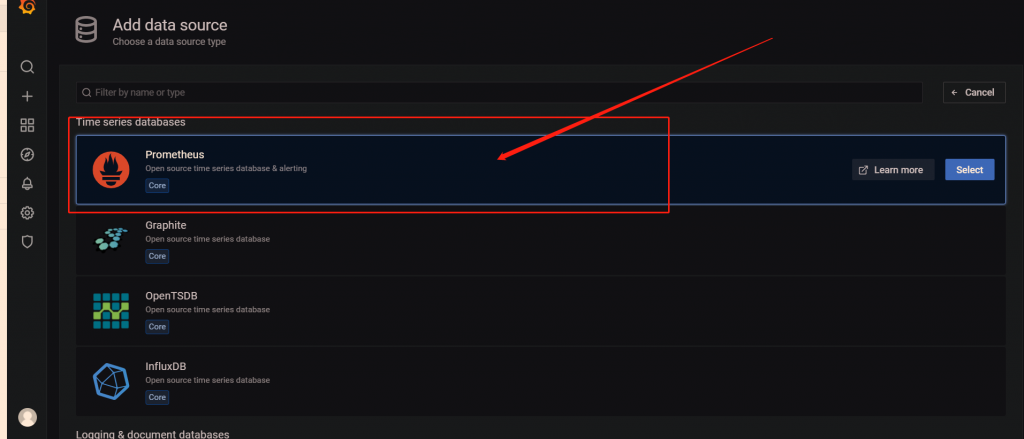
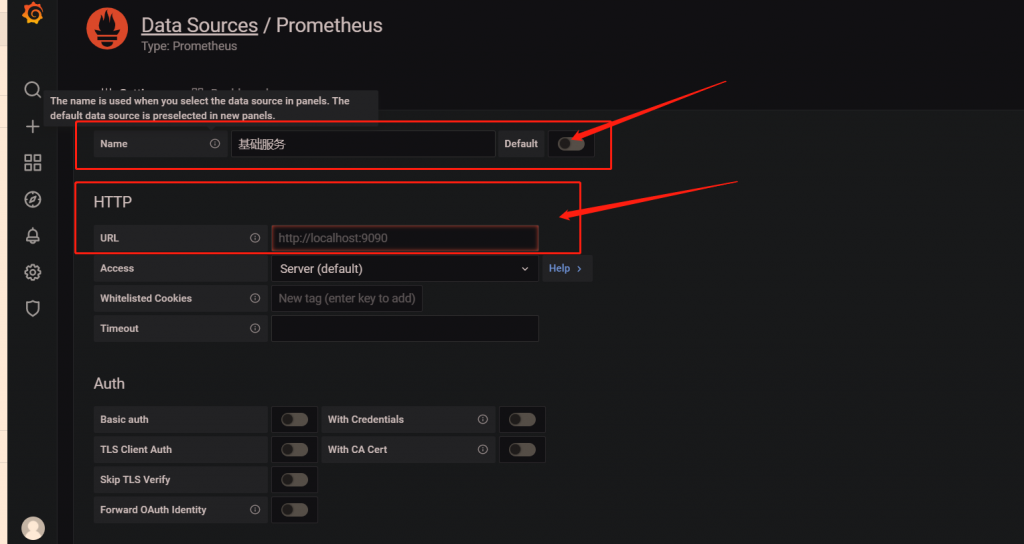
你仅需配置这两项即可,第一项为数据源设置一个名字(随便写,我这里随便写一个叫基础服务的数据源)
第二项:请填写你Prometheus 的地址
最后点击保存即可
2.3.2 配置 dashbord 和 pannel
这里要介绍一下 dashbord、pannel、datasource (数据源) 三者的关系了。
pannel 就是一个监控面板,你可以理解为它就是一张图表
多个 pannel(图表) 将会摆在一个 dashbord 上
而 pannel 的数据来自 datasource 数据源
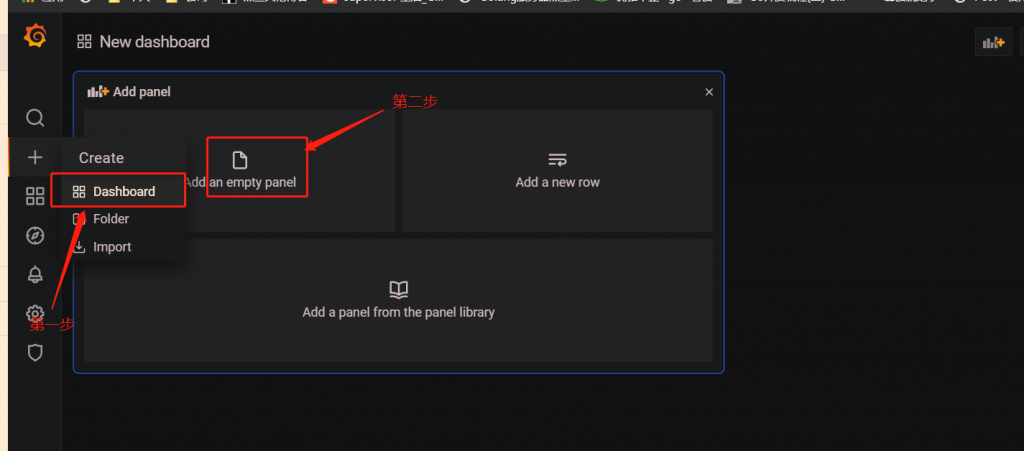
我们先配置 dashbord和 pannel
如下图所示请依次点击:

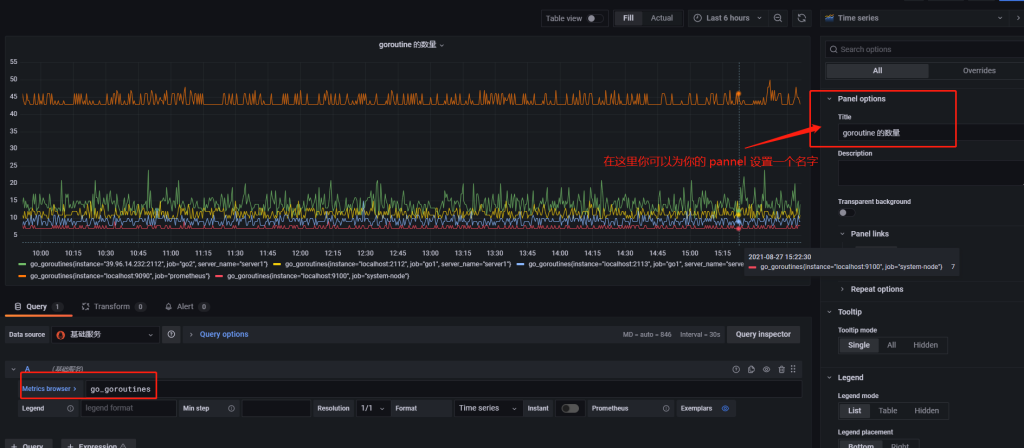
监控指标来自于 /metrics 下的数据,这里我填写的是 go_goroutines
再点击右上方的 save 按钮即可保存
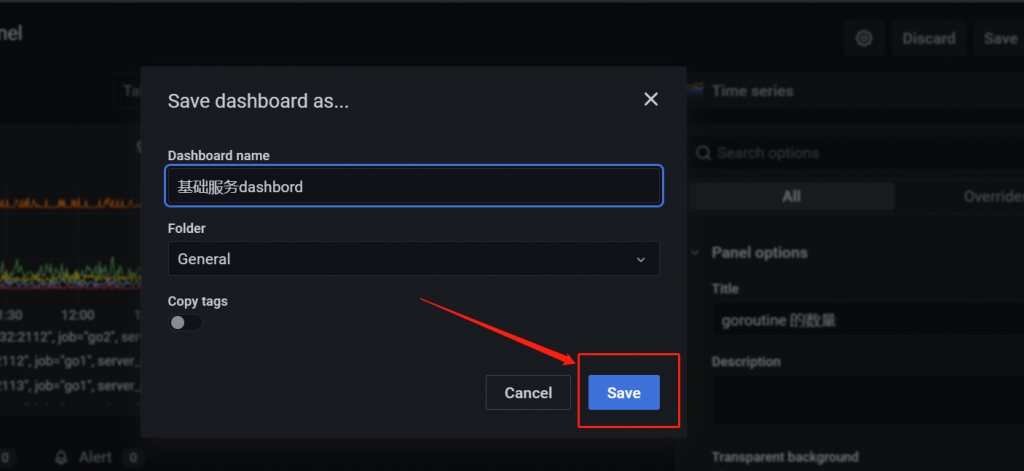
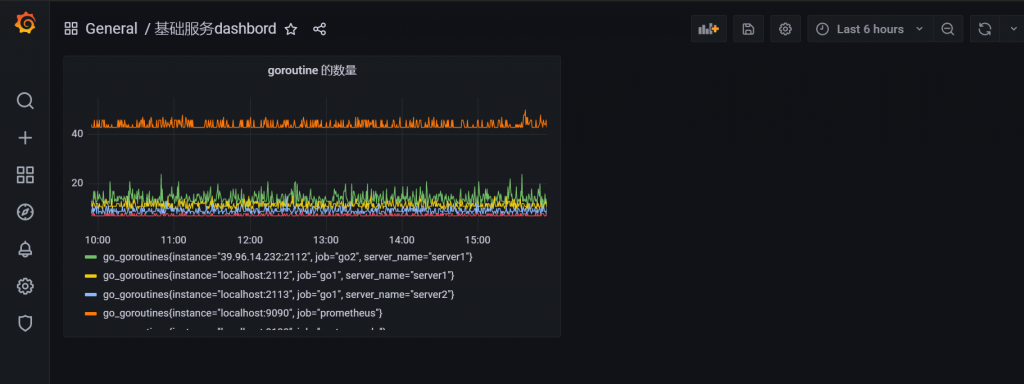
这样一张粗略的,监控goroutine 的图表就完成好了
但是我们知道,我只是想监控 go1 机器的 server1 、server2 以及 go2 机器的 server1 而下图的这一串并不是我们想要的,杂乱无章,我该如何将它规整呢?
如下图所示,这一串监控杂乱无章,我想将它按机器和服务进行分类

如果能做成下面这样的图表就好了,
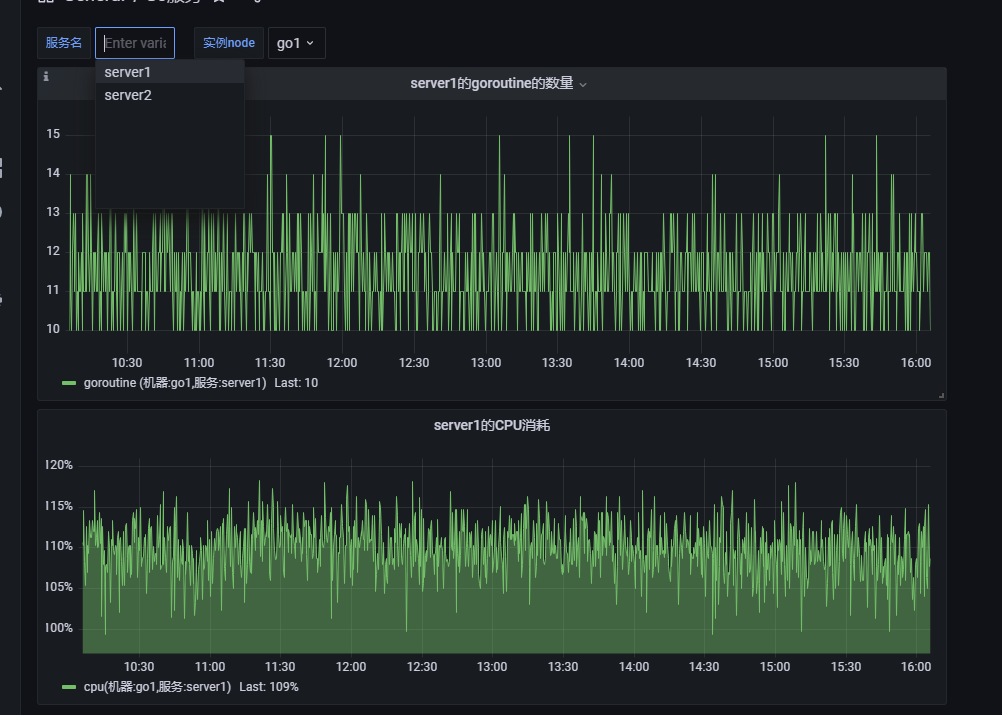
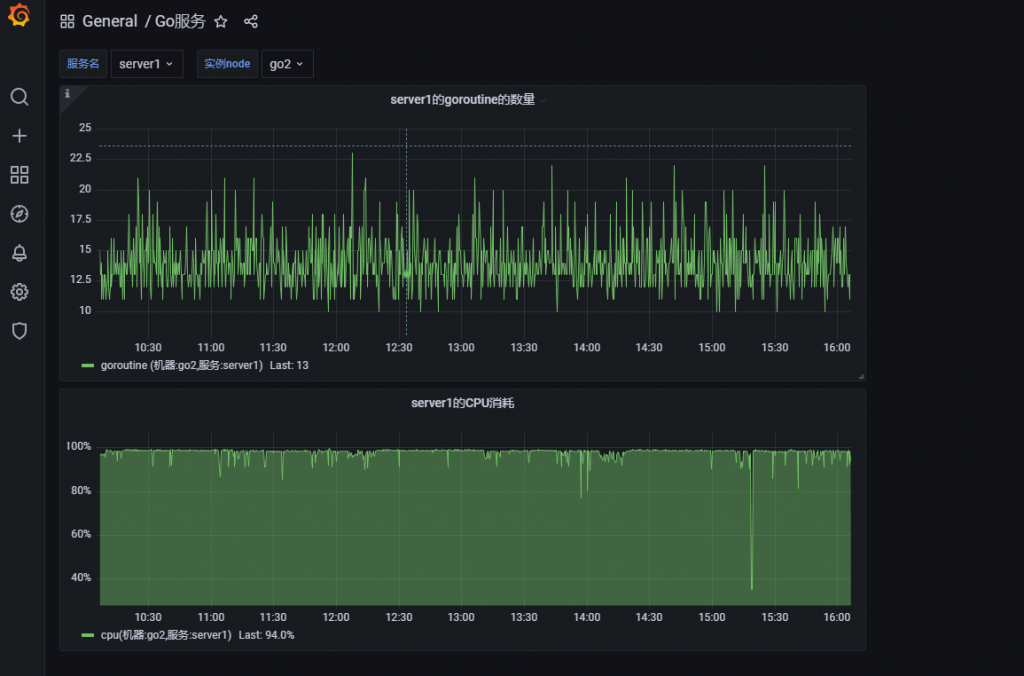
这里就需要引出 Grafana 的 Variables (变量) 的使用了。
还记得吗,我们开始为 promethus.yml 配置了一些标签,如下图所示:
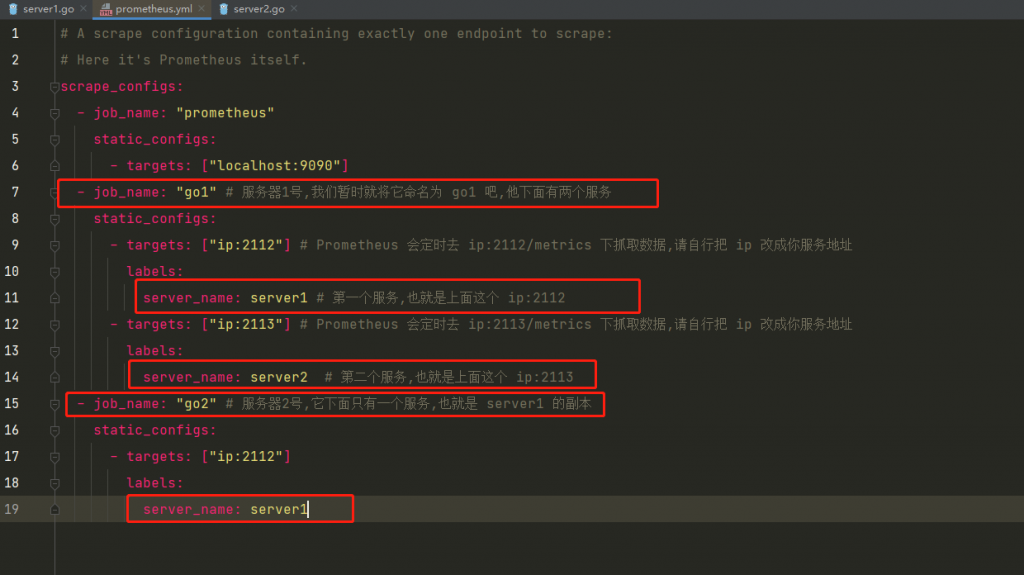
标签 job_name 和 server_name 均可以作为我们的筛选条件来使用。
首先我们需要添加两个变量
先开始设置机器的变量,变量名就叫 job_name
第一步点击设置
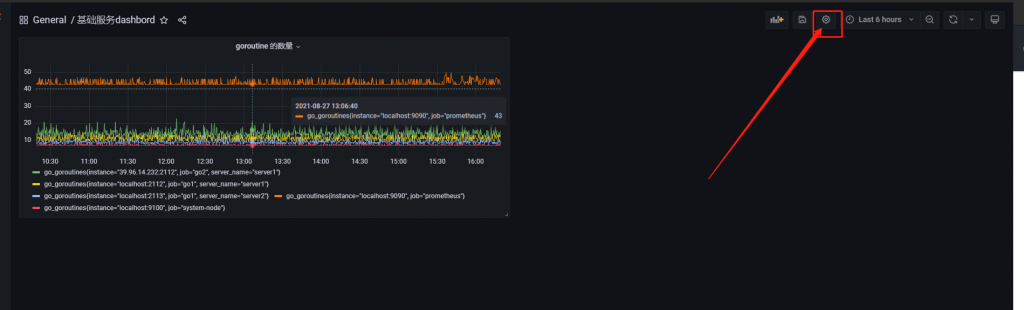
第二步选择变量
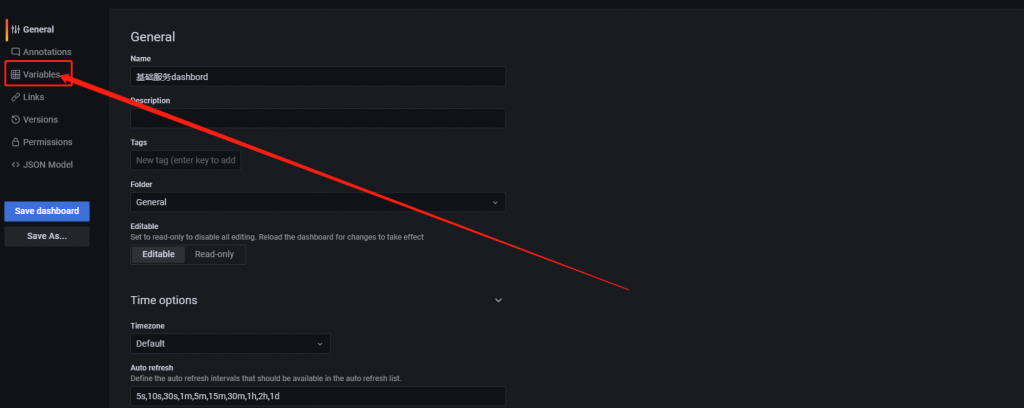
第三步设置变量
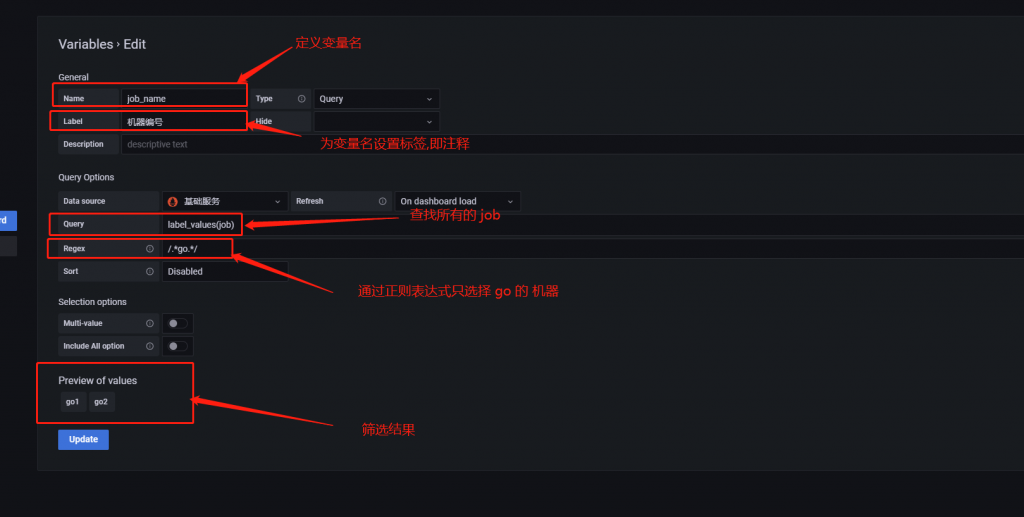
job_name
机器编号
label_values(job)
/.*go.*/最后点击保存即可
再设置
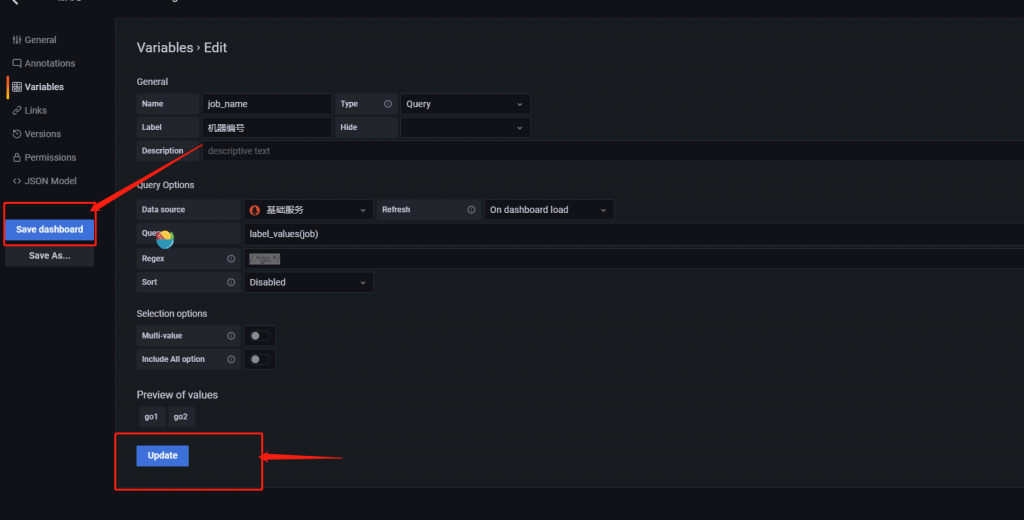
再设置一个服务的变量,变量名就叫 server_name
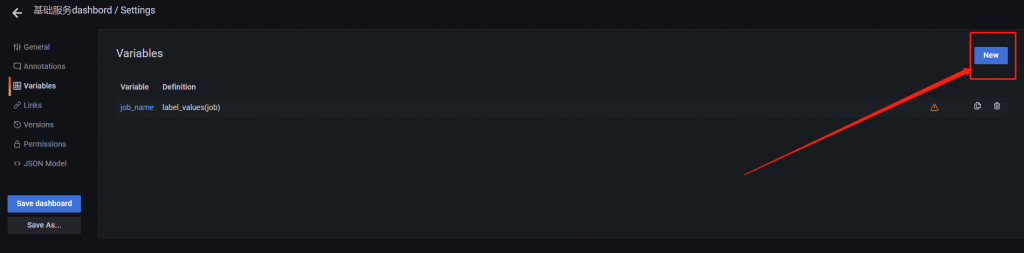
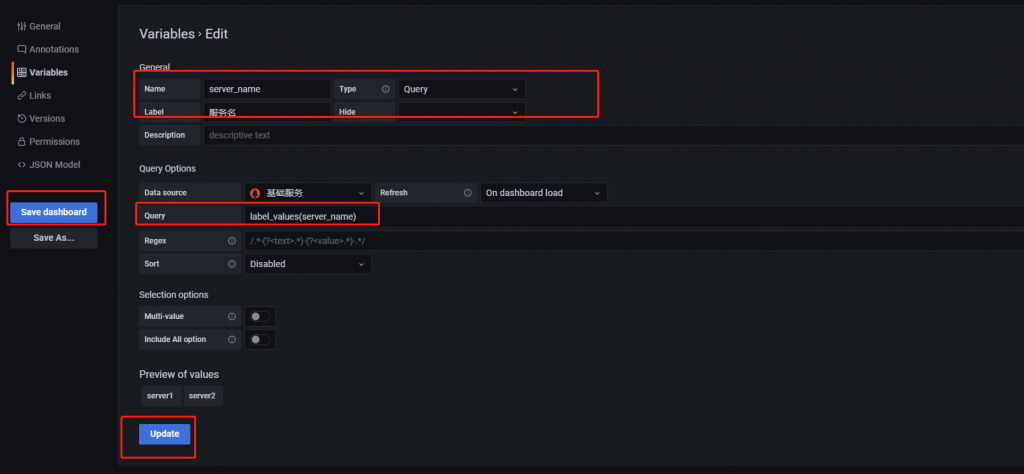
保存即可。
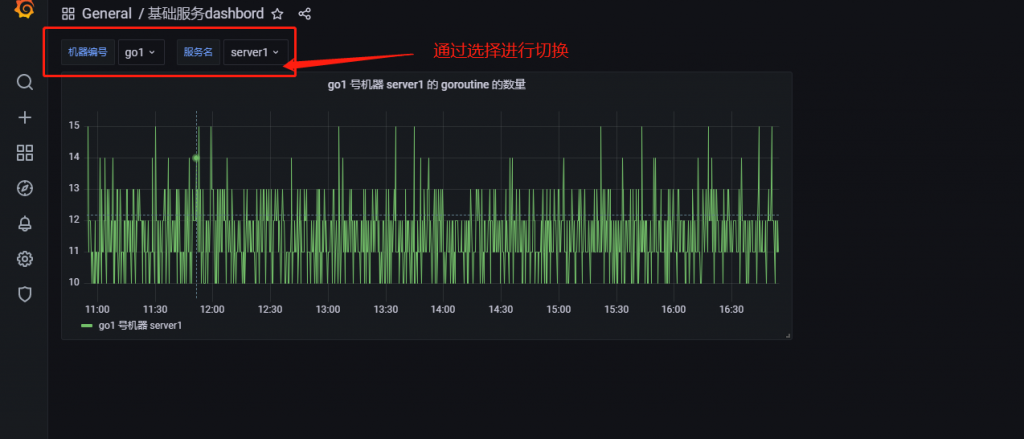
至此,我们的两个变量就已经设置完了,我们可以从图表上方看到多了两个选择框,如下图所示
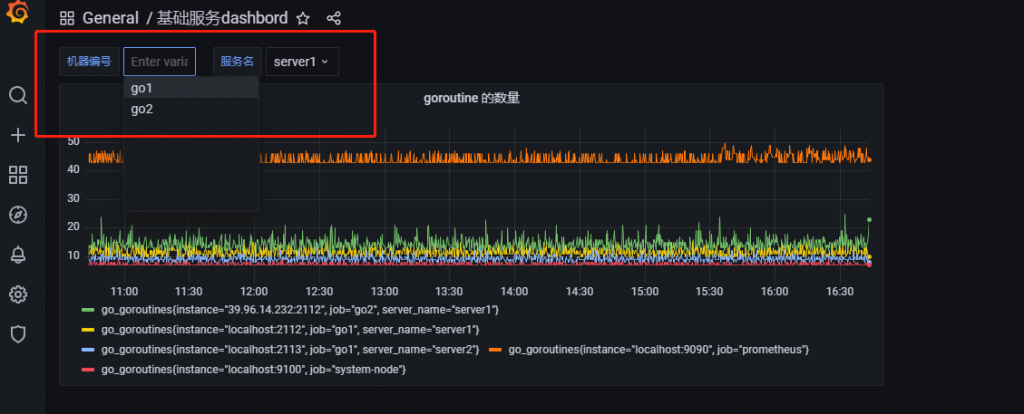
现在我们的任务就是选择指定的选项,下方就能展示指定图表。
现在我们就从原有的图表基础上进行修改
修改原有的 pannel 如下图所示
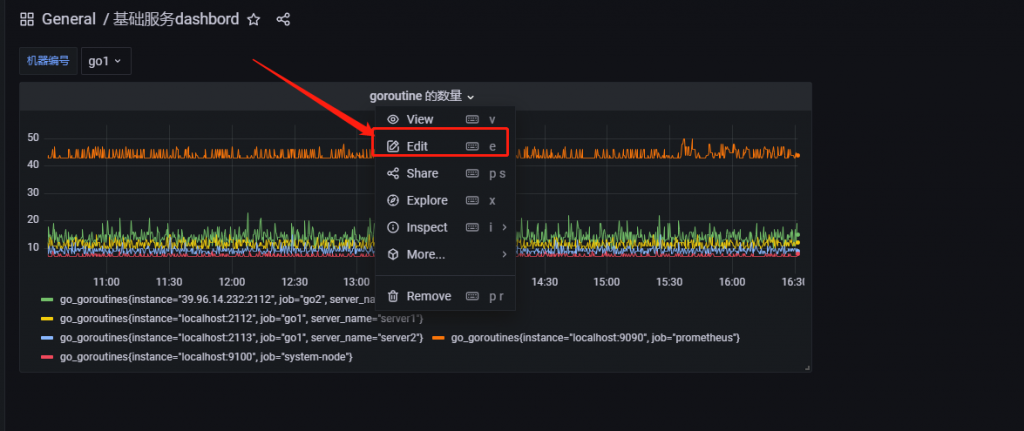
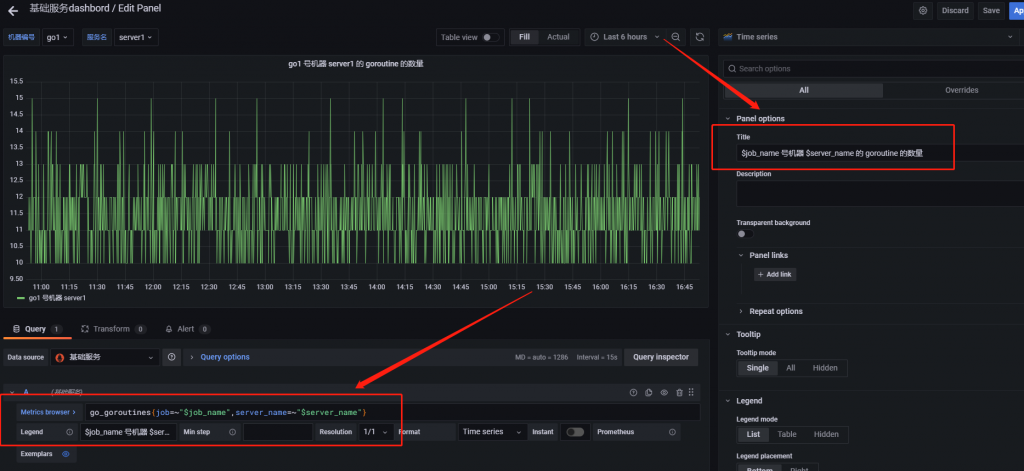
go_goroutines{job=~"$job_name",server_name=~"$server_name"}紧接着点击 Save 保存即可。
至此,你就能在面板中看到单独的服务了
我们可以再为 dashbord 添加一块 pannel 用来监控项目的CPU
老样子选择新增pannel
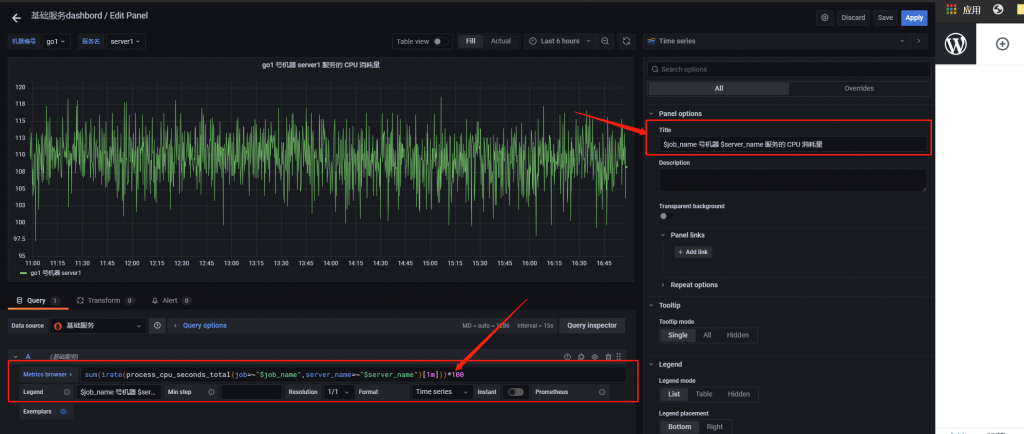
sum(irate(process_cpu_seconds_total{job=~"$job_name",server_name=~"$server_name"}[1m]))*100设置单位百分比
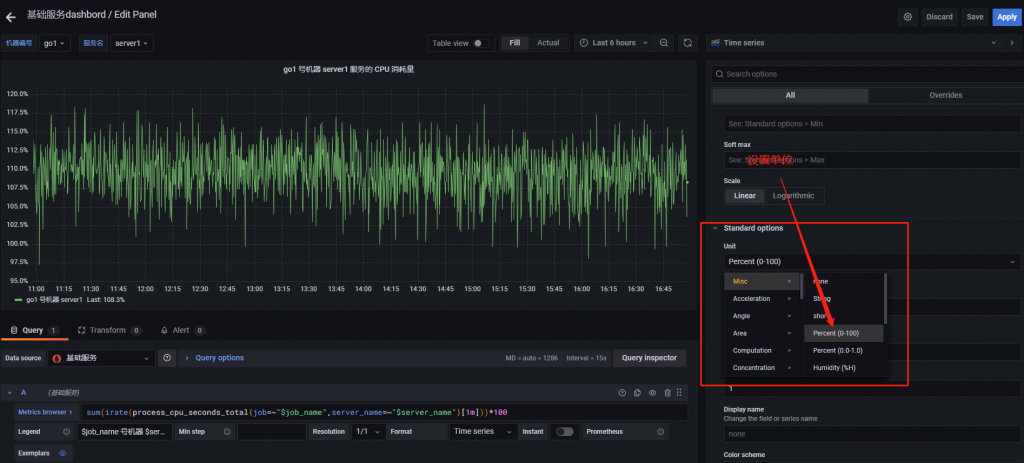
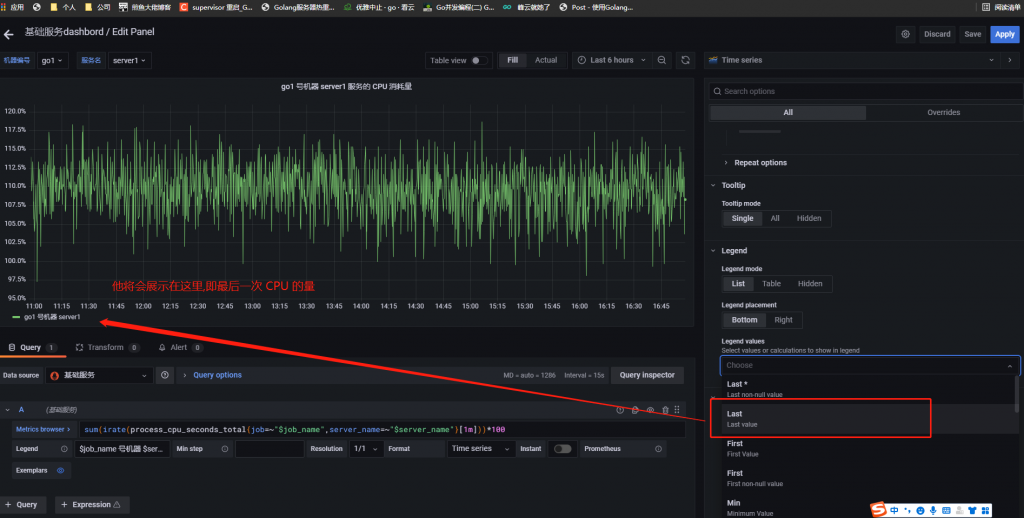
点击保存即可。
至此,图形化监控就做好了。
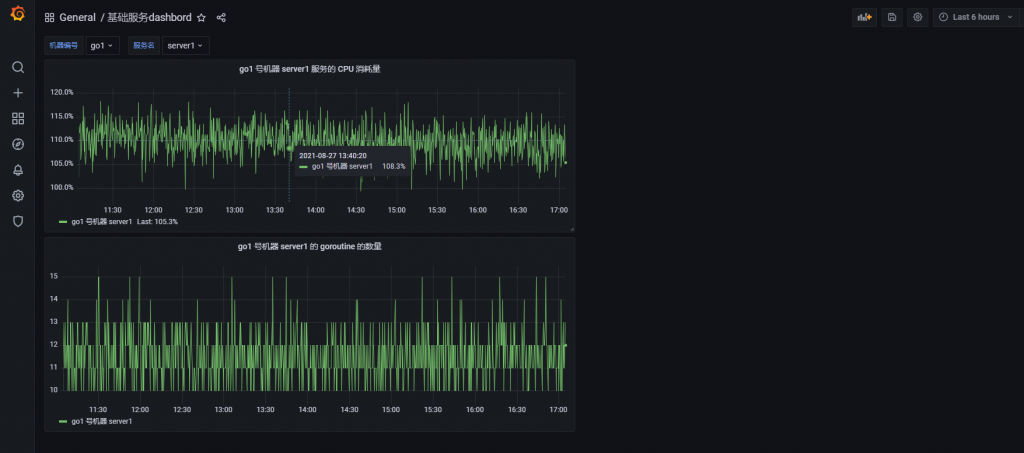
你还可以根据自己的喜好进行新增,这里就不一一举例了。
兰陵美酒郁金香
大道至简 Simplicity is the ultimate form of sophistication.
文章评论(0)