一、前言
这是一个有趣的话题。
承接上篇文章用 WireGuard 整了个三层组网游戏加速方案,发现 WireGuard 客户端和服务端之间主要采用的是 UDP 协议传输。
网友都说 UDP 加速器在打游戏时国内的运营商也会有 QOS 限制,所以体验起来也不佳。
他们常用的方案是采用 udp2raw 这种开源解决方案
用 Raw Socket 在 IP 报文的基础上伪造 TCP 协议头。使得报文长得像 TCP ,但实际不是 TCP 。
这种方案的好处在于绕过了内核协议栈的拥塞控制算法。并且达到欺骗运营商设备,使其误以为这是一个 TCP 报文从而解决 QOS 限制上的问题。
但是为什么 WireGuard 不支持 TCP 传输。如果 WireGuard 直接支持 TCP 传输是不是没这么多问题了?
为此我继续贴一下当初的游戏加速架构图如下所示
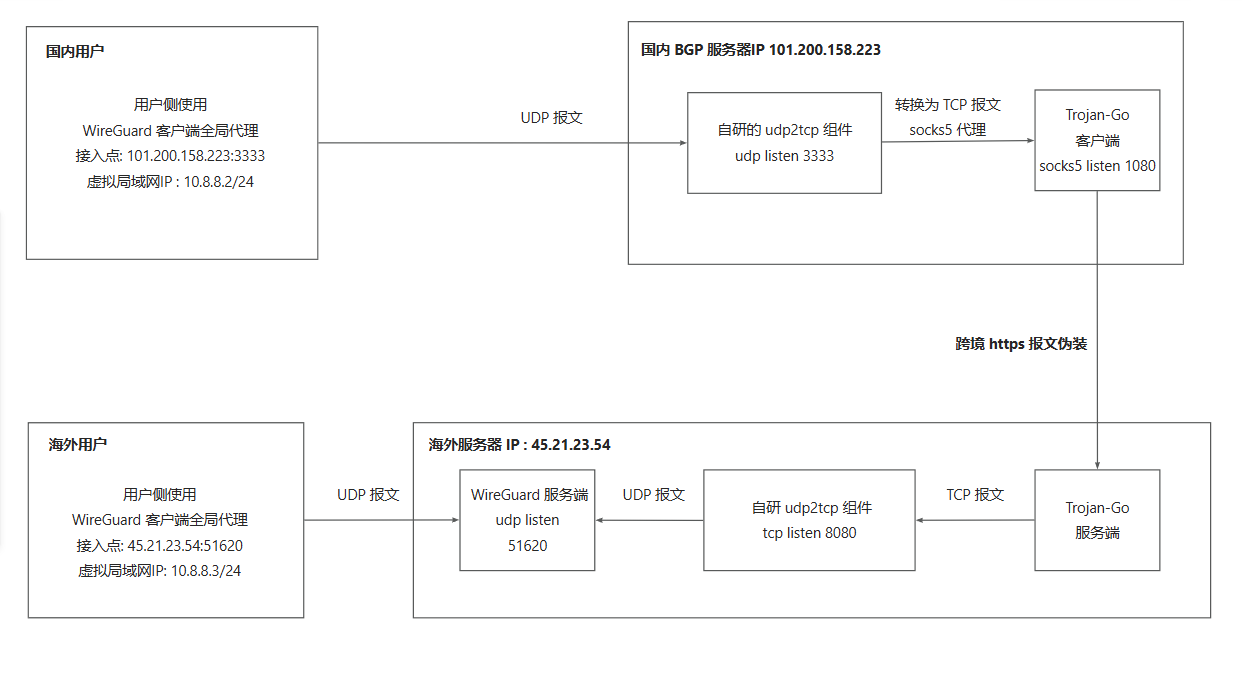
图中 国内用户 到 国内 BGP 服务器 之间是使用 UDP 传输的 VPN 协议。但运营商会对家宽发出的 UDP 报文进行 QOS 限制。
那么这一段路如果用 TCP 实现又会怎么样? 会解决运营商封 UDP 的问题吗?
如果是,那么为什么 VPN 不直接用 TCP 协议去传输呢?
这就回到了文章的标题。
二、TCP over TCP 造成的雪崩问题
这个问题还是得细化到微观层面去分析。
我们看一个应用程序通过 VPN 发送数据报文给目标服务器的情况,流程如下所示:
应用程序---->数据报文 [网络层[传输层[应用层[payload data]]]] ----> VPN 虚拟网卡 wg0 ----> VPN 客户端 ---->
----->[VPN 的 UDP/TCP 报文+ VPN协议头+应用程序[[网络层[传输层[应用层[payload data]]]]]]----------> VPN 服务端 ----->目标服务器
假设 应用程序 发送的 TCP 报文,分别为报文 1、2、3 、4 。每个报文长度为1
假设序列号seq=1开始,报文1的seq则是1,报文2则是2 依次类推
网络数据包被成功路由到虚拟网卡 Wg0,成功转发给了 VPN 客户端。
此时 VPN 客户端和 VPN 服务端创建 TCP 链接。为了简单起见,VPN 转发应用程序报文,序列号刚好也从1开始。
即内层应用程序的 TCP seq=1 对应 VPN 的 seq=1。内层发了4个报文,VPN也发了4个报文。双方一一对应依次类推
但 VPN 客户端在给 VPN 服务端的公网传输环节丢了 VPN 报文2 。
即 VPN 服务端收到了报文 1、3、4
因此 VPN 服务端那边会返回 SACK 给到 VPN 客户端。 报文形式如下
SACK (确认序列号报文1的seq+1 "我收到了1,我期望你从2开始传") [3,5) 我额外还收到了报文3,报文4
简写: SACK (ack=2) [3,5) 注: SACK 只描述 ACK 之后额外收到的零散块,不会已经 ACK 的 1 继续放到 SACK 块中。因此不会有 [1,2)
并且此时,由于 VPN服务端的TCP协议栈收到了报文1 、3、4,协议栈会将报文1交给上层VPN程序并通过网卡 + SNAT 的形式发送给目标服务器。
因此目标服务器也会返回报文1的 ACK 报文,再通过 VPN 服务端->客户端--->给到应用程序。
这里注意 VPN 服务端的 TCP 协议栈并不会把 报文3、4 给上层 VPN 程序。因为队头阻塞问题 报文2 丢了。3、4的发送至少等到报文2的抵达。否则他将一直夯在 TCP 接收缓冲区。自然目标服务器也接收不到
我们来继续梳理一下这个过程,看看各方都收到了什么
- 首先是 应用程序 所在的协议栈只收到了来自目标服务器返回的报文1的ACK。至于报文2、3、4都没收到。
- 其次是 VPN 客户端所在的内核协议栈,收到了 SACK (ack=2) [3,5)。 此时内核协议栈发现少了报文2,因此触发快速重传报文2,但是这个过程还没结束
这都造成了什么? 首先,报文3、报文4一直被夯在 VPN 的 TCP 接收缓冲区,因此自然也没到达 目标服务器,自然 目标服务器 也不会返回 ACK
很明显,因此应用程序感知到 RTT 变长了。直到应用程序所在的 TCP 协议栈触发了RTO (超时重传)又将报文2、3、4重传了一遍。
回想一下,应用程序所在的协议栈它有必要重传报文3、4吗? 因为它压根没丢,只是被夯在服务端的接收缓冲区没发给目标服务器罢了。
加上外层 VPN 客户端自身由于 SACK 也会重传报文2。导致本就脆弱的网络又更加拥堵了。
应用程序所在的协议栈由于 RTO (超时重传) 瞬间将 cwnd 发送缓冲区降为 1 。
好家伙,瞬间没包可发了。这就是 TCP 拥塞控制堆叠触发的反作用。
三、再来看看 TCP Over UDP 的情况
假设 VPN 是用 UDP 协议进行传输的。应用程序发送报文 1、2、3、4
UDP 没有队头阻塞,没有拥塞控制。发送给 VPN 后,全部发给了目标服务器。就算中间的报文 2 丢了。目标服务器也收到了报文 1、3、4。
因此目标服务器发起 SACK (ack=2) [3,5) 返还给应用程序所在的TCP协议栈。
此时,应用程序所在的协议栈触发快速重传。
快速重传的降窗最多 cwnd/2 ,并且能快速恢复。
没有多余的重传动作,一切都是那么的和谐。
四、结语
最后我找 AI 给我生成了一份图例作为解释。有兴趣的可以看看
https://www.xhyonline.com/subsite/tcpovertcp/tcp-over-tcp.html
兰陵美酒郁金香
大道至简 Simplicity is the ultimate form of sophistication.
文章评论(0)